

Why python recommendation systems are important
The most common and smartest way for e-commerce websites to display relevant items to their clients is to use an automated system. This system will be in charge of calculating the probability of similarity between items or user preferences. These systems are called recommendation systems, recommender systems or recommendation engines. A recommender system is one of the most well-known applications of data science and machine learning. In this article, we will go over Python Recommendation Systems.
In fact, almost every major tech company has applied them at some point. Amazon recommends you products, Spotify recommends you music, Google recommends you search results, and YouTube recommends you videos. It is such a common practice that, in 2009, Netflix offered a million dollars to anyone who could improve the accuracy of its movie recommendation system by 10%.
These systems help us with The Paradox of Choice, a known problem that is caused by the rapid increase in the amount of data and the effects of this abundance: managing the information becomes more difficult and this can lead to information overload.
Recommender systems have great commercial importance; they have changed the way websites communicate with their users, increasing interaction to provide a richer experience by autonomously identifying recommendations for individual users based on the user’s past purchases and searches, as well as their behavior.
What are the types of python recommendation systems?
Recommendation systems can be classified into 3 types:
Simple recommenders
This is the type of recommender we will build in this article. It offers generalized recommendations to each user, based on each element’s attributes. In a movie recommendation scenario, it will make recommendations to each user based on movie genre, movie rating or movie title. An example of a simple recommender is IMDd’s Top 250.
Content-based recommenders
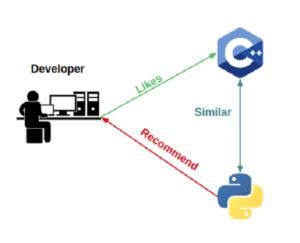
These recommenders suggest similar items based on a specific one, taking into account each user’s preferences. This system uses item metadata and the general idea behind it is that if a person likes a particular item, they will also like a similar one. This does not involve other users, just each individual’s preferences. Based on what you like, the algorithm will pick items with similar content and recommend them.
It will never recommend products within categories the user has not bought or liked in the past. So, for example, if a user has watched or liked only action movies so far, that’s the only genre the system will recommend.
Collaborative filtering engines
The collaborative filtering algorithm uses user behavior to select the items to be recommended. These systems are widely used and do not require item metadata like their content-based counterparts. There are different types of collaborating filtering techniques and we’ll look at them in detail below.
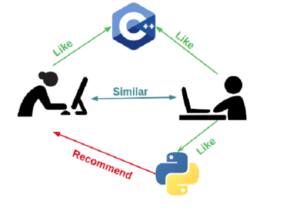
User-User collaborative filtering
This algorithm finds similarities between users grading a score in the process. Based on this score, it picks the most similar users and recommends products that they have previously liked or bought. Essentially, it generates a prediction for item A based on how other users in the neighborhood rated it.
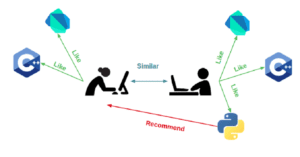
Item-Item collaborative filtering
In this case, the algorithm computes the similarity between each pair of items. Similar items are identified based on how people have rated them in the past. For example, if Julia, Christian, and Vic have given 5 stars to The Lord of the Rings and Harry Potter, the system identifies the items as similar. Therefore, if someone buys The Lord of the Rings, the system also recommends Harry Potter to them.
Why Python Recommendation Systems? 
You can build this system in virtually any language, but Python certainly takes the most points in this particular field. Python offers readable code for complex algorithms and versatile workflows in machine learning and AI. Python allows you to put all the effort into solving a machine learning problem instead of focusing on the language itself.
Moreover, Python is easy to learn since its code is easy for people to follow, which makes it easier to build models for machine learning. Python is more intuitive than other programming languages. It has many frameworks, libraries, and extensions that simplify the implementation of different functionalities.
Today, we will be using some of those libraries:
 Scikit-learn: Machine Learning in Python
Scikit-learn: Machine Learning in Python
Scikit-learn offers simple and efficient tools for predictive data analysis. It is accessible to all and reusable in various contexts. It is built on NumPy, SciPy, and matplotlib. Moreover, it’s open-source and commercially available under the BSD license.

Pandas is a data analysis and manipulation tool. It was built on top of the Python programming language. This tool is fast, powerful, flexible, open-source and easy-to-use.

NumPy is the fundamental package for scientific computing with Python. Nearly every scientist working with Python draws on the power of NumPy. With this power comes simplicity: a solution in NumPy is often clear and elegant.
Build a simple movie with Python recommendation system
We will be working with Jupyter Notebooks, but you can just find the code in this repository; there you’ll find this file and the dataset used in this example.
According to its website, “Jupyter Notebook is an open-source web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text. Uses include: data cleaning and transformation, numerical simulation, statistical modeling, machine learning and much more.”

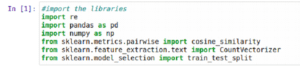
First, we will import all the necessary libraries for this lab.
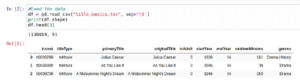
Then, we’ll load the dataset, which we obtained from the IMDb Datasets of all movies uploaded in a certain period; we will use a reduced test dataset just to save computer resources.
title.basics.tsv.gz – Contains the following information for titles, as can be see in IMDb’s website:
- tconst (string) – alphanumeric unique identifier of the title.
- titleType (string) – the type/format of the title (e.g. movie, short, tvseries, tvepisode, video, etc.).
- primaryTitle (string) – the most popular title/the title used by the filmmakers on promotional materials at the point of release.
- originalTitle (string) – original title, in the original language.
- isAdult (boolean) – 0: non-adult title; 1: adult title.
- startYear (YYYY) – represents the release year of a title. In the case of TV Series, it is the series release year.
- endYear (YYYY) – TV Series end year. ‘\N’ for all other title types.
- runtimeMinutes – primary runtime of the title, in minutes.
- genres (string array) – includes up to three genres associated with the title.
Then, we’ll split the dataset into train and test. We will be using only 13k movies instead of all the data records, and we won’t shuffle the data so we know which movies will be in our test data.
We are also creating a new Movie_id for our test dataset which will help us later on.


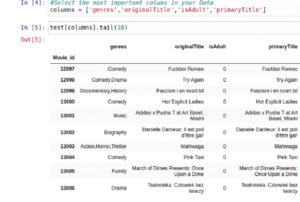
We’ll select the most important columns in our dataset, that is, the ones that we will use to make a movie prediction.
We’ll check if there is any missing data in the most important column in our dataset; if that is the case, we will clean the data by removing all null values.
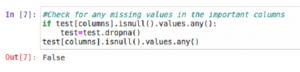
Then, we’ll define a function that will create a new column, combining all the important column values into one string for each record in our dataset.

We’ll create the new column for our dataset.
We will create a new variable named cm that will contain a matrix of token counts for each important_features value.

Then, we’ll create a new variable named cs; this will store a matrix of the similarities between each important_features record for each movie, meaning it will include how similar each pair of movies in our dataset is.

This is a number between 0 and 1, we can see that the diagonal is 1 because each movie is 100% similar to itself.
We can check the size of this matrix, which will be Numbers of Movies * Numbers of Movies.

So, time to start the recommendation part. We will have a movie that the user has seen and we will recommend a similar movie to that one. In our example, the movie that the user has seen will be ‘Art of Falling in Love’, ID ‘12870’
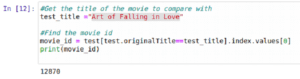
*Notice that it has to be an existent movie in the dataset and that, if you change it, you’ll have to change the test*
Now, we will create a list of all the similarity score values for all the movies compared to the movie we’ve chosen. (Meaning get a column or a row in the cs matrix).

Once we get it, we’ll sort it from most to least similar.
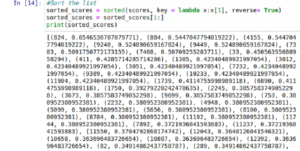
And we’ll show the top 10.
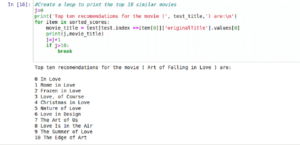
Great Work!
Looks like it’s working for romantic movies, but, to test it properly, we should test another genre. To do this, we’ll create a function we can call.
We actually wrote 3 functions; let’s have a look:
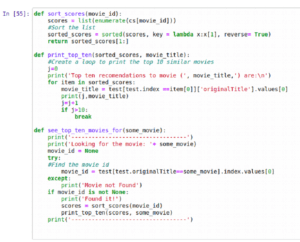
We are basically doing the same thing, but generalized for any movie so we can test our program, and called print a few times to make it more readable.
Let’s check how it works.
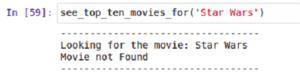
Ok, the exception looks good!
Let’s see a real result now.

Great! All of them are Alien/Galaxy related, looks good enough.
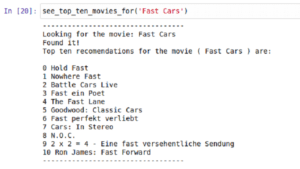
I’m not sure all these movies are entirely similar, but this can be due to our dataset, or even our training selection. In any case, our simple recommendation system has passed the test for sure!
Congratulations! You should be proud of yourself!
What do you think? Can this be improved by collaborative filtering? Would you take up the challenge?
Final thoughts on Python Recommendation Systems
The machine learning world can be overwhelming, but as you can see, it’s not rocket science! Anyone can build a basic system that works, and it can certainly save you time and money in your e-commerce business. Imagine recommending 1000 movies on our own! You would need an entire team to sort through the data, but with automation, it falls into the probability and statistics world, and it can be coded.
So we encourage you to delve deeper into this world, and hope this information helps you!


